Sincerely yours is back from travels to his European lair, Delft where he went to talk about analog integrated circuits, diagnostics, design, and as the Dutch say “koetjes en kalfjes” (a very cute way to say, small talk). In the meanwhile, the AI chip company Cerebras pronounced its dinner-plate multi-core chips a success, went public and while I respect a bit the hardware nature of the business, cannot but recollect Vespasian’s words “Pecunia non olet” (money does not stink) when he imposed tax on urine. Of course, since the IPO, the stocks of the AI chip company in question started falling and somehow I have the feeling this is only the beginning. If I was of the Las Vegas inclination, I would short the AI. El Reg reported that Gemini was successfully used in a complicated scheme to steal crypto currency and it is of a minor curiosity that the crook prompted the engine in Russian while the responses were in English. Automation at its best.
On a less Friday-note I managed to extract an assurance from my TU Delft non-sycophantic human friends that a technology I am working on to provide better Verilog/VHDL technology mapping is not a total hallucination and has fleeting chances of success. More about this in an upcoming blog.
I also went to Delft and talked with a friend about Model-Based Diagnostics, something that used be an AI discipline before the chat-bots vulgarized the term AI. This friend knew about Lydia and the difficulty of modeling the real-world as a system of Boolean equations or a switching circuit. The same friend, didn’t know that after I finished my Ph.D. I spent quite some time figuring the analog alternative of Lydia and extending it.
As I wrote before, Lydia was a system for diagnosis of switching circuits. The process, was somewhat related to model checking. My task was to deal with the computational complexity, which, surprisingly, although very bad in the worst-case was never too bad in practice. Meaning, it was very difficult to come-up with a system that is difficult to diagnose.
The real-problem was, that switching circuits are mostly useful for modeling and designing digital circuits, state-machines, Von Neumann machines and in generals parts of computers. Switching circuits are no good for almost anything physics. This is related to the old debate of causation versus correlation, or the fact that there is no logical implication in physical systems. In other words, in physics and biology, almost everything is some kind of a circuit, almost always with feedback.
Lydia-NG is trying address the difficulty of modeling of physical systems. Of course, I had to provide compatibility with the old Lydia, so I was trying to define diagnosis as multiple simulations, with somewhat random configurations. The configurations that led to simulation predictions close to the actual measurements, would form the diagnostic hypotheses.
I managed to compile and run Lydia-NG and I am in the process of modernizing it. In addition to Boolean systems, Lydia-NG is capable of diagnosing and simulating systems of Ordinary Differential Equations (ODEs), and SPICE models of electrical circuits. SPICE models of electrical systems are somewhat more difficult systems of systems of Differential Algebraic Equations but about that I will talk another time.
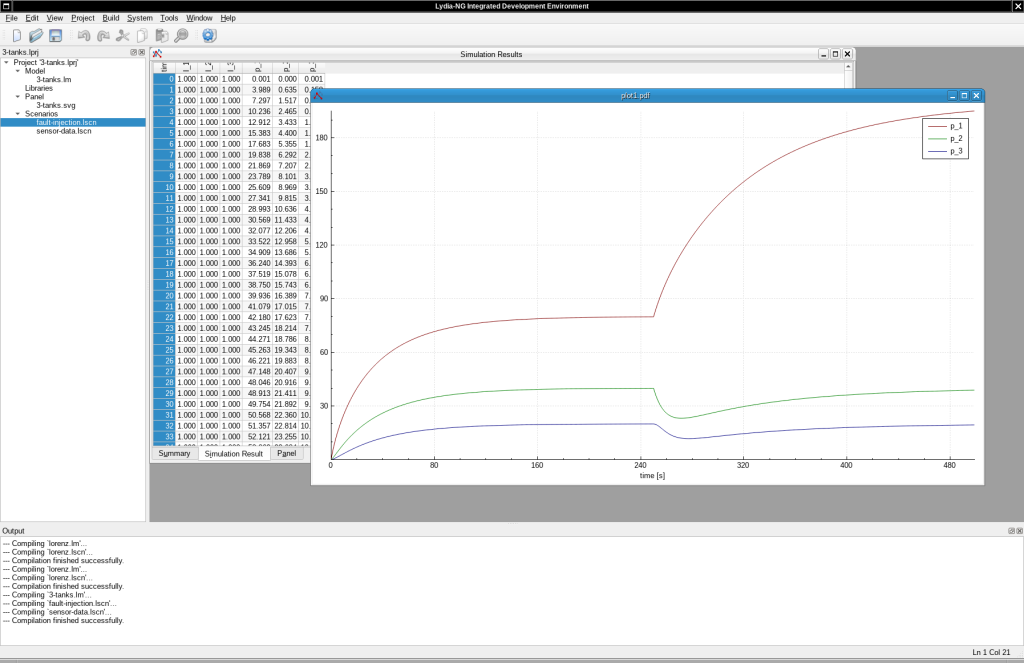
Lydia-NG is implemented in C++ and also has an IDE. Below is a simulation of the “Hello, world!” of diagnosis of a chemical system consisting of three connected vessels. You can see what happens whenever there is a leak.
I am in the process of modernizing and finishing Lydia-NG and it and I am thinking on how to release it–open source or otherwise. There is a whole lot to be said about diagnosis of equations and simulation of DAEs, there are also languages like Modelica and communities dedicated to the topic.
There is more to come when talking to state estimation, diagnosis, simulation, and continuous systems. I have implemented techniques like Kalman filters, variations of the latter like Extended and Unscented Kalman Filters (EKF and UKF), particle filters, and many others. Actually, at some point Xerox PARC was trying to prototype a system for diagnosis where tools such as Kalman filters were the core reasoning engine of diagnostics. But about this story, I will write another time.
In another non-development, my application for the South Park Commons, a place for kibitzers to raise money from the naive tech angel investors by talking nonsense, was denied. One can only think of Groucho Marx’s famous quote: “I refuse to join any club that would have me as a member.“
Field-Programmable Gate Arrays and the languages for programming (ahem, configuring them) have the reputation of being difficult to master. I still remember when I heard for the first time: at the beginning of my Ph.D. studies at TU Delft, a new friend of mine, visiting the computer engineering department, came home and told me he was supposed to implement some kind of GPS signal processing that required a lot of linear algebra operations with vectors and matrices (duh, isn’t all computing, including the insanely large vector matrix multiplication of LLMs, like that).
What stroke me at the time is that my friend thought he could just automatically translate Matlab code to VHDL (this is the European version of Verilog, for you Yankees) and benefit from the “micro-parallelism” of the platform. During this phase of my studies, I was already told that turning a sequential algorithm and making it parallel cannot be done by a machine.
But I am diverging. Years later, I still have problems with saying that we program FPGAs. Verilog, VHDL, and SystemC are not classical programming languages like C++ and Python. They have both declarative features for synthesis and procedural features for simulation and fancier techniques like model checking (here I come with my novel ideas and techniques). For the actual physical manifestation of an FPGA like transforming input electrical signals to output signals, the term “FPGA configuration” is more apt than programming. But a job ad for FPGA configurator would sound strange, thus FPGA programming it is!
Demo
Let us fast-forward to the demo. I have felt numerous times the gusto of blinking a LED, so what could be better compared to a bunch of them. In the video below, you can see in action the auto-generated Verilog from the previous article combined with driving the 7-segment LED of the Basys-3.
Of course, this has been done sufficient times and is at the level of a high-school student, if it were not for the connection to the AXI bus, the behavioral simulation and the composition of IP blocks.
Composability and an AXI Architecture for Synthesis
In my previous article on the topic of FPGA, I showed that not all Verilog should be manually written. To do that, I went to implement common digital circuits in Python, saving them as DSLs and translating to Verilog. Of course, testing these circuits with real FPGA hardware requires a lot of infrastructure, and I used Vivado soft processor to do that. Vivado provides a quick graphical way to connect various IP blocks.
I will make a small deviation here. Although these days the boundaries between hardware and software are fuzzy, there is far less open-source hardware than open-source software. The reasons are, I believe, two: first, shipping hardware costs, on top of your time, also cash. The second reason, I believe, is more psychological: that developing hardware provides less instantenous gratification than developing software. That is why the building blocks of electronic chip design are called IP blocks where IP stands for Intellectual Property. Anyhow. Because companies still want to provide closed-source, obfuscated IP blocks, Vivado provides methods for composing these blocks into architectures. And if you want to be anybody in the chip making business you have to adhere to these practices.
One should always be suspicious of acronyms that have both the words Advanced and eXtnsible in them (the I in AXI stands for Interface). But this one is good. It is a part of AMBA and is a standard for chips to connect fast with each other. This is not unlike SPI or I2C, only faster and with many wires.
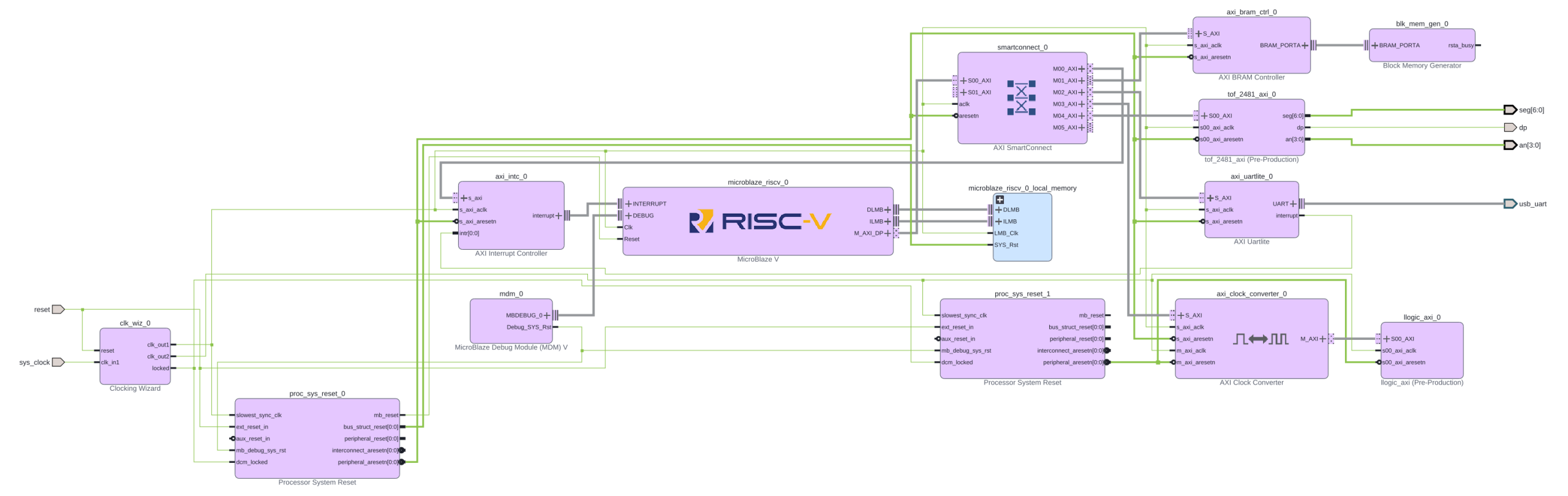
In the previous blog, I showed you the IP block diagram for the RISC-V architecture that uses autogenerated logic circuits. For the demo that follows, I have developed another IP block that drives the 7 segment LEDs of the Basys 3 development board. The new IP block diagram that includes this LED control block is shown below.
AXI Architecture for Simulation
Because simulation is distinct from synthesis, it is handy to have a separate Vivado block diagram for simulation. The reason is that we need a lot of infrastructure to generate the AXI bus signals, and this is already provided by the big players who have skin in the AXI game: AMD, ARM and the likes. It would be very difficult to toggle all AXI signals of a transaction by hand (remember that an AXI-compliant IP has tens of ports; one has to address a 32-bit address space, for example). Thankfully, this is already done by an IP block that contains only simulation code and is called “AXI Verification IP”. The resulting block diagram for the simulation is shown below.
It turns out that to connect to such a beast as an AXI-bus; it does not use the relatively basic simulation primitives of the original Verilog. One needs more abstraction, and it is provided by the dynamic extended features of System Verilog which extends the original Verilog for system verification. The code excerpt below shows the gist of the test-bench and illustrates how easy it is to generate an AXI transaction.
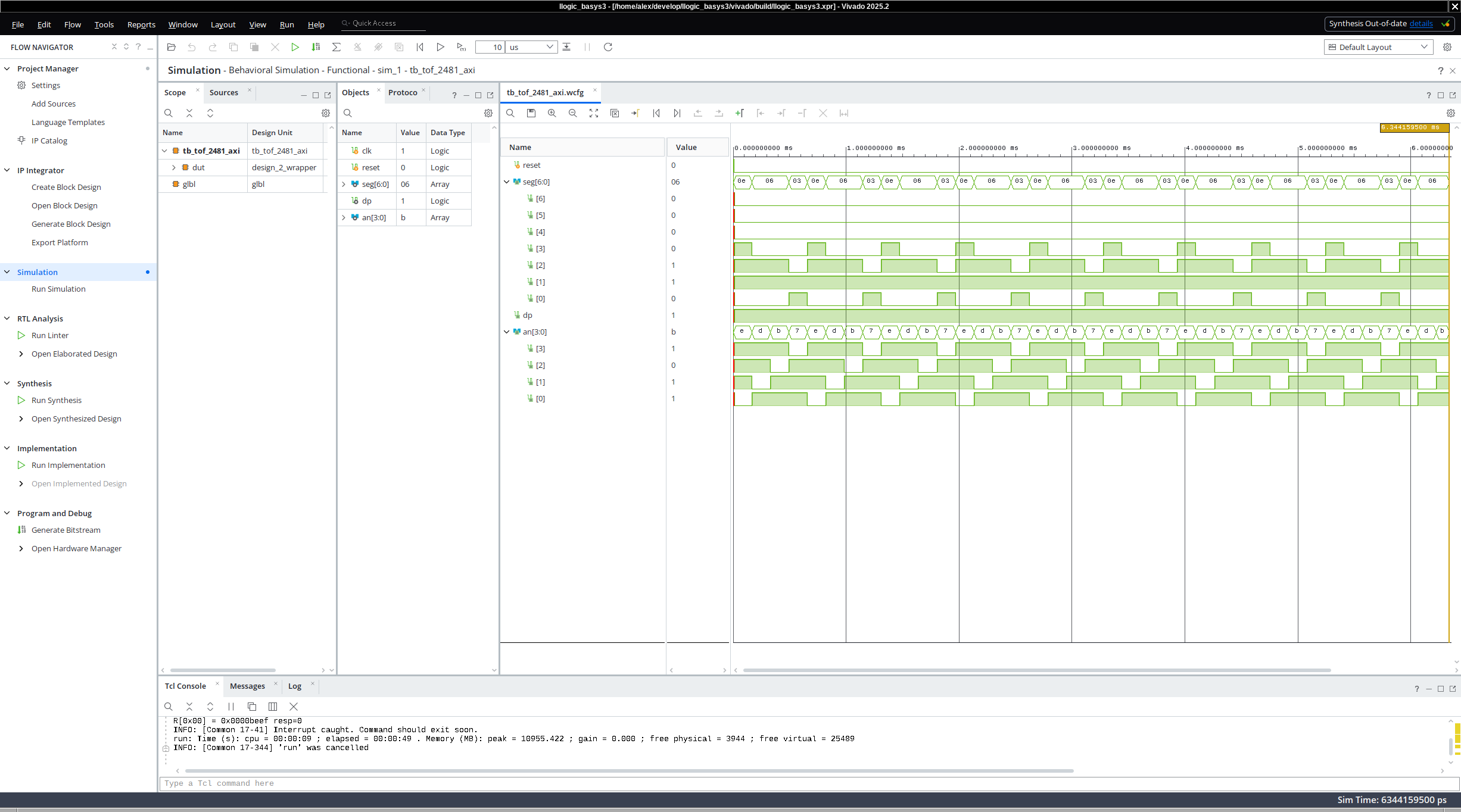
Having concocted the above test-bench for sending the input signals to the simulation of the AXI connected 7-segment LED display, we can click in Vivavdo, and lo-and-behold, wave-forms come out.
Of course, to perform even further testing and validation of the seven segment LEDs, one could convert the individual signals driving the LEDs to hexadecimals signals and could compare what the LEDs show to what the AXI master sent (in our case the hexadecimal value of 0xbeef). But the journey toward model checking, automatic diagnostics and testing is more interesting, and we have discussed LEDs more than enough.
Reflection
FPGA programming tool chains and Vivado are a hairball of design by committee, we do something this way because we did it the same way when we were young and when we used to bike ten miles to school every day (uphill both ways and into the wind). On the more positive side, these are complex tools, and they work, and people use them for their digital design.
All that being said, our understanding of both the theory and practice of computing has improved dramatically since the mid 20-th century, and it is time to revisit these old ways of designing and implementing circuits. If we do this carefully, maybe, maybe, we will design the hardware, software, and even AI algorithms that are not shameful to write about and use.
What is Next?
In what follows, we will grow our demo and I will show you how crappy the actual FPGA implementation that Vivado does. We will also discuss more accurate simulations, clocks, frequencies, timing analysis, and what proper AI algorithms (not the ones everybody is discussing but the ones that are not used for fraud and deception).
The Real Deal
Unlike what is these days practice in most of the Silicon Valley, everything I talk about is accessible and reproducible. So here is the repository that allowed me to write this blog article and make the demo: https://gitlab.llama.gs/llogic_basys3
Ceterum censeo slopem esse delendam.
(Cato the Elder ended every speech in the Roman Senate with “Carthage must be destroyed” — regardless of the topic. This is that, but for AI slop.)
Today’s journey back in time is going to take us to 1993 in post-communist Bulgaria. It was only a few years after one day at school we were told to stop addressing the teachers as “comrade” and start using the “Mr.” and “Mrs.” honorifics.
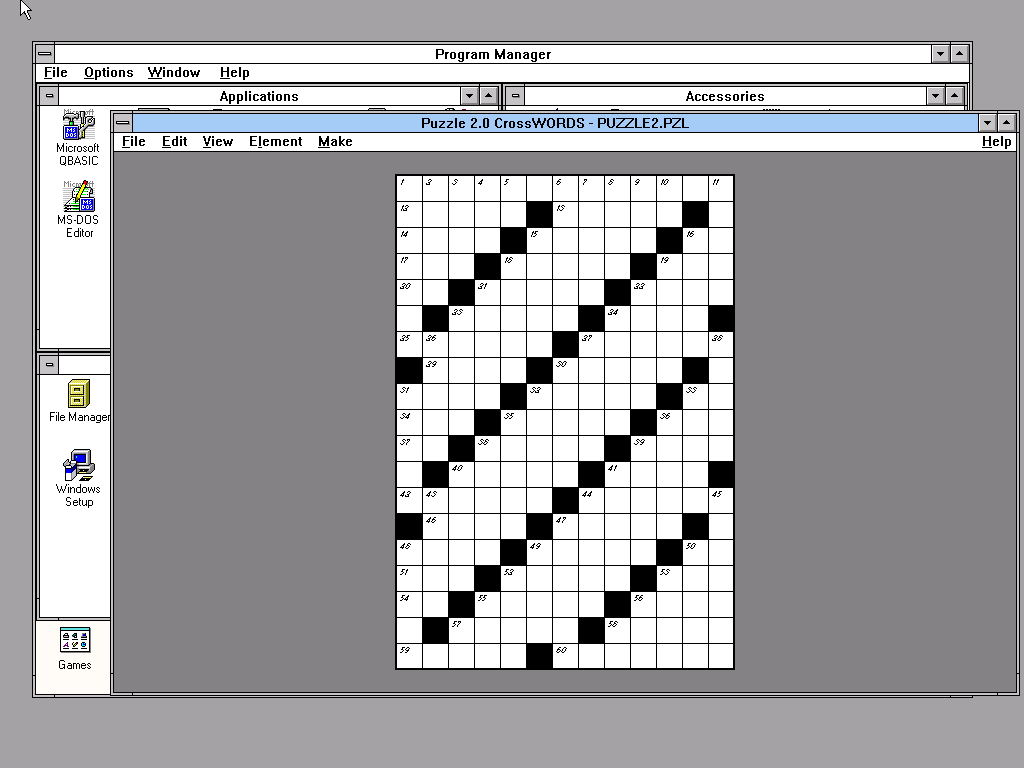
I was going to school, and my computer was a Bulgarian clone of the IBM XT. I think at some point I had 20MB hard drive but I am not sure about that. Doing what many of the lucky generations did, I was hanging out at computer clubs while one day somebody challenged me to write a computer program that generates crosswords.
So I did. Today I dug it up, compiled it, and put the sources on my GitLab server, for no other reason but to entertain the reader. Sadly, I lost the knowledge of Bulgarian Cyrillic code tables, so there is a nice little project for when I have time.
I remember that CPU power was same expensive during the years and I often left friends’ PCs with the state-of-the-art blazing fast at the time 80486 Intel process overnight to generate the crosswords that I was selling to the local Varna newspapers. It would take an hour to make a moderately small crossword puzzle. I ran the program yesterday, and it took a few seconds to fill the grid of the crossword shown above.
At the time I didn’t know that the problem is NP-hard, but I designed my algorithm to be sound and complete and I am a bit proud of my teenage self given that the OpenAIs and Anthropics of the Mecca seem to have forgotten this exact type of human knowledge. I guess Altman or Amodei were too busy fraternizing to take CS 101 or logic.
Expect next week: more on using real computer science and algorithms for EDA and hopefully on Friday VmWare images generating crossword puzzles with Windows 3.1 and a small digression to a clone of Wordle.
Ceterum censeo slopem esse delendam.
(Cato the Elder ended every speech in the Roman Senate with “Carthage must be destroyed” — regardless of the topic. This is that, but for AI slop.)
In the background of all this, I am quietly growing my circuit analysis and synthesis framework. Last week I wrote about DSLs and their advantages. Today I decided to implement the parser. It took me half an hour, and this is the lark grammar:
Just out of curiosity, I wanted to see how bad the slop generator is, and ChatGPT did not fail to disappoint. I will not put here the generated grammar as I want to preserve the reader’s sanity, but it is ugly and 71% longer. It also generated an Abstract Syntax Tree that is 36% bigger. If I was a research assistant in compiler construction, such a homework would immediately get grade five (in The Netherlands, where I studiedwent to university) grades are from one to ten, one to five are all failing grades, I suppose it is good to know that you almost made the exam).
Of course, this grammar produces an Abstract Syntax Tree that has too much detail for good analysis. Luckily, Lark provides AST transformation classes which promise to be tidy and neat and different from slop. That is what is going to be my next GitLab push.
Ceterum censeo slopem esse delendam.
(Cato the Elder ended every speech in the Roman Senate with “Carthage must be destroyed” — regardless of the topic. This is that, but for AI slop.)
Bitcoin miners are liquidating their holdings to pivot into AI hosting. The machines that wasted electricity producing imaginary money will now waste it producing imaginary intelligence. Anthropic has secured 3.5 gigawatts of compute — the consumption of three and a half million households — to serve language models.
GCC compiles the entire Linux kernel in fifteen minutes on a single machine drawing 200 watts. Fifty watt-hours. A light bulb left on for an afternoon. It manages this because it is not guessing. It has a grammar, a type system, and an optimisation pipeline where every transformation preserves semantics. There is no temperature parameter. There is no “try again and hope.”
A compiler’s cost is \(O(n \log n)\) in the size of the input. A language model’s cost is \(O(n \cdot d)\) where \(d\) is the dimensionality of a model that cannot tell you whether the answer is correct. When the task has a formal specification, you do not need gigawatts. You need a parser.
I have been writing parsers for twenty years. Today I started improving the one that matters most: the circuit description language at the heart of llogic, qbf-designer, and the formal methods toolchain I am building at Llama Logic.
My first encounter with a compiler was at Zend Technologies in Ramat Gan in 2000. I was twenty-two, fresh off the plane from Bulgaria, and I did not know what a parser was. Zend built the PHP language engine. I watched a small team turn a grammar into a working language that ran half the web. I did not understand how.
A few years later, at Delft, I read the Dragon Book and took the compiler construction course of Koen Langendoen. We became friends over my many years at the university. That course turned out to be one of the most useful things I have ever learned. It is the skill that lets me write software that works — not approximately, not statistically, not when the vibes are right, but deterministically, on all inputs, by construction.
It is also how I got into diagnosis. At the end of my master’s I went to Koen and asked for a Ph.D. position in compiler construction. He told me “compilers are passé” — but I could go work with Arjan J.C. van Gemund doing diagnostics. Arjan has since retired north to compose music, which is a better use of a fine mind than supervising Ph.D. students, though he was good at both. They needed a compiler for LyDiA, the diagnostic modelling language. So I built one. Then I built many more. Every research system I have worked on since — LyDiA, the DXC framework at NASA Ames, the synthesis tools at PARC, and now llogic — has a parser at its core. The compiler is never the point. The compiler is always the point.
A domain-specific language is a small language built for one job. SQL is a DSL for databases. Regular expressions are a DSL for pattern matching. Makefiles are a DSL for build dependencies. You do not write an operating system in SQL. You do not query a database with a Makefile. The language fits the problem, and because it fits, it can enforce constraints that a general-purpose language cannot.
This is the point that the vibe-coding movement misses entirely. A grammar is not a convenience. It is a contract. When I write a parser for a circuit description language, the grammar specifies exactly what constitutes a valid circuit. If you misspell a gate type, the parser rejects your input. If you connect an output to a nonexistent signal, the parser tells you. If you instantiate a module that does not exist, you get an error message with a line number — not a plausible-looking circuit that silently computes the wrong function.
This is what determinism means in practice. The parser either accepts or rejects. There is no 95% confidence. There is no temperature. The same input produces the same result every time, on every machine, for every user. A QBF solver receiving a malformed netlist will produce garbage. A diagnosis engine receiving an inconsistent model will compute meaningless results. The parser is the gate that keeps garbage out. It costs milliwatts. It works.
There is a second reason, less often discussed. Humans need to read these things. An engineer debugging a faulty adder needs to look at the circuit description and understand it. A reviewer verifying a synthesis result needs to confirm that the specification matches the intent. This is not a machine-to-machine format. It is a language — with the same design obligations as any language: clarity, consistency, and the ability to say exactly what you mean and nothing else.
The circuit DSL in llogic had outgrown its grammar. The new format adds modules, arrays, imports, and arbitrary nesting. A full adder, from primitives to a 4-bit module with array slicing:
# 4-bit ripple carry adder
import "std_logic.circ"
module half_adder(input a, b; output s, c):
x: s = xor(a, b)
a: c = and(a, b)
end
module full_adder(input a, b, ci; output s, co):
wire f, p, q
inst half_adder ha1(a=a, b=b, s=f, c=p)
inst half_adder ha2(a=ci, b=f, s=s, c=q)
o: co = or(p, q)
end
module adder2(input a[2], b[2], ci; output s[2], co):
wire c0
inst full_adder bit0(a=a[0], b=b[0], ci=ci, s=s[0], co=c0)
inst full_adder bit1(a=a[1], b=b[1], ci=c0, s=s[1], co=co)
end
module adder4(input a[4], b[4], ci; output s[4], co):
wire cm
inst adder2 lo(a=a[0:1], b=b[0:1], ci=ci, s=s[0:1], co=cm)
inst adder2 hi(a=a[2:3], b=b[2:3], ci=cm, s=s[2:3], co=co)
end
Four levels of nesting. Modules, arrays, slices, named connections. The flattener — a recursive tree walk, the same algorithm I used in LyDiA for system descriptions — traverses the instantiation tree and emits the flat netlist the solver has always consumed. The hierarchy is for the engineer. The solver does not know it exists.
Sequential circuits work the same way. A 4-bit serial adder with synchronous reset:
A dff with one argument is a plain register. Two arguments: synchronous reset. This maps directly to the standard Verilog template always @(posedge clk) if (rst) q <= 0; else q <= d; — making translation between the two languages mechanical.
So why not just use Verilog?
Because Verilog is a simulation language that has been coerced into serving as a synthesis input. A synthesis tool reads an always block, pattern-matches the sensitivity list, and infers what is a register and what is combinational logic. The engineer writes behaviour and hopes the tool’s heuristics match their intent. In llogic, a dff is a dff. An and is an and. There is no inference. The circuit says what it is.
This matters for formal methods. Diagnosis requires knowing exactly what components exist. Synthesis requires a precise specification of the design space. Neither tolerates a language that hides structure behind inference rules. Verilog is the right language for RTL designers who want to describe behaviour and let tools figure out the structure. Llogic is the right language when the structure is the point.
The parser, AST, and flattener should take a few days. When they are done I will update the llogic repository on the feature/hierarchical-dsl branch.
Three and a half million households’ worth of electricity to serve a model that cannot tell whether it is thinking deeply or not. Fifty watt-hours to compile a kernel. Considerably less to parse a circuit. The tools that work have always been quiet, small, and correct. The software will continue to not hallucinate.
Ceterum censeo slopem esse delendam.
(Cato the Elder ended every speech in the Roman Senate with “Carthage must be destroyed” — regardless of the topic. This is that, but for AI slop.)
It is Friday. KPMG, the consultancy behemoth that delivers business Venn diagrams for outrageous prices, informs us that 70 percent of UK business leaders will keep spending on AI even when they can’t prove it does anything — the consultancy helpfully suggests we stop calling it “investment” and start calling it a “strategic enabler for enterprise-wide transformation,” which is the corporate equivalent of renaming a hole in the ground a “subterranean opportunity space.”
Meanwhile, OpenAI has put Stargate UK on ice, citing the cost of electricity and the regulatory environment, mere months after announcing it during a Trump state visit — one assumes the due diligence was conducted with the same rigour as the naming convention.
AMD’s AI director reports that Claude Code has become “dumber and lazier” since February, based on analysis of 6,852 sessions and 234,760 tool calls, which is the most thorough performance review any AI has received and rather more than most human employees get. One notes that the AWS CEO, asked whether AI is overhyped, described the question as “one of the funnier questions I get” and then asked a room full of people who had each paid $4,000 to attend an AI conference whether they believed in AI. Asking turkeys to vote on Christmas, as it were.
In this climate of expensive credulity naïveté, I thought we might spend a Friday doing something that we do on Fridays: looking backwards. Reverse engineering — the art of taking something apart to understand what it does — is the intellectual opposite of the current AI approach to technology, which is to build something enormous, declare it transformative, and hope nobody asks what it actually computes.
The Правец (Pravetz): Bulgaria’s Apple II, Give or Take an Iron Curtain
I grew up using Правец (Pravetz) computers — forgive the Cyrillic, but we Bulgarians invented the alphabet, even though half the Slavic world claims the credit, and besides, it makes any noun look like classified military hardware. Every Bulgarian of a certain age used one. The Правец 82 was the machine in my school, with its yellow plastic case, black keyboard, red RESET key, and the unmistakable aura of a computer that had been reverse-engineered from a capitalist original by engineers who had never seen Cupertino and didn’t need to.
My first encounter with a personal computer was typing in a BASIC program that drew Lissajous figures in hi-res graphics. I was in the fourth grade. It was 1987. But I am digressing.
IMKO-1 PC
The story of the Bulgarian computer is worth telling properly. In 1979, engineer Ivan Marangozov at the Institute of Technical Cybernetics and Robotics (ИТКР) in Sofia built the IMKO-1 — the first Bulgarian personal computer. It was a clone of the Apple II, and “clone” is doing some diplomatic heavy lifting here: the ROM was identical, the schematics were identical, the 6502 CPU ran at the same 1 MHz. The differences were a metal case that could double as ballast, a linear power supply heavy enough to qualify as exercise equipment, and the replacement of lowercase Latin with uppercase Cyrillic — because behind the Iron Curtain, you didn’t do lowercase. The keyboard used 7 bits for character codes, so Cyrillic overlapped with Latin lowercase. A limitation, but also an engineering decision that had a certain brutal elegance: you get one alphabet at a time, comrade, and you will type in capitals.
The rumours of how this was accomplished are better than the facts. The Bulgarian intelligence services allegedly sent operatives to procure Apple IIs from the West — less James Bond, more cartoon characters getting drunk on capitalist Coca-Cola while trying to buy a computer with a heavy accent and a suitcase full of leva (the Bulgarian currency, not then known for its convertibility). More interesting is what happened next: an institute in Sofia was reportedly tasked with decapping the ICs, lifting the netlists under a microscope, and reproducing them with socialist lithography — the equipment for which was probably lifted from the Dutch. The reasonable question is why arguably clever people went through all of this when designing an ALU from scratch is not that difficult, but we will leave this armchair philosophy question to the LLMs. They have the confidence for it, if not the answer.
Today, people do this sort of thing voluntarily and for fun. The 6502.org community hosts dozens of homebrew computer projects — enthusiasts building 6502-based machines from scratch on breadboards, complete with VGA output and SD card storage, using parts that are still in production. The MOnSter 6502 takes it further: a fully functional 6502 processor built from 3,218 discrete transistors on a circuit board the size of a dinner plate, with LEDs showing the state of every register. What the Bulgarian state did with an institute and a five-year plan, hobbyists now do in garages on weekends.
Marangozov was, depending on your perspective, either rightfully accused of cloning the Apple II or laudably credited with delivering computing to an entire country that couldn’t buy one. The truth is both, and neither is shameful. Apple II schematics were published. Steve Wozniak intended the design to be understandable. What Marangozov and his team did was take a published design, source the components (Bulgarian and Soviet clones of American chips — clones all the way down), adapt the character set, and manufacture hundreds of thousands of units that shipped to every school and scientific institute in the Eastern Bloc. By the mid-1980s, Bulgaria was producing 40 percent of the personal computers used in COMECON countries. Not bad for a country whose communist leader Todor Zhivkov — a peasant’s son turned printer’s apprentice who rose through the party ranks on the strength of Soviet patronage and the convenient absence of anyone more threatening — happened to have been born in the village that gave the computers their name. Правец was a hamlet of no consequence until Zhivkov turned it into a town by decree in the 1960s; by the 1980s it was assembling the flagship technology of the Eastern Bloc. One does not need a diagnostic engine to detect the fault in this particular circuit of patronage.
The later models improved substantially. The Правец 8M integrated a Z80 alongside the 6502, letting it run CP/M. The 8A was a proper Apple IIe clone with expandable memory. The military version had an integrated terminal design, because of course it did. There was even a Правец 8D, which broke ranks entirely — it was a clone of the British Oric Atmos, presumably because even Bulgarian engineers sometimes want variety.
The point is not that Bulgaria copied Apple. The point is that reverse engineering — understanding a design well enough to reproduce and adapt it — was how an entire generation of engineers learned computing. We didn’t have access to Stanford or MIT. We had schematics, soldering irons, and a cheerful disregard for intellectual property law that was, in fairness, philosophically consistent with the economic system. The Правец was my first computer. Everything I know about hardware starts there: with a 6502, 48 kilobytes of RAM, and a cassette recorder that worked when it felt like it.
Hayes and the ISCAS Circuits: What Were They For?
Now here is a story about reverse engineering that is less well-known outside the EDA community but is, in its own way, just as delightful.
The ISCAS-85 benchmarks are the standard test circuits for digital design research. If you work on test generation, fault diagnosis, synthesis, or timing analysis, you have used them. They were released by Franc Brglez and Hisashi Fujiwara in 1985 as a “neutral netlist of 10 combinational benchmark circuits” — gate-level descriptions of real circuits, stripped of context, for the research community to use as common benchmarks.
There was just one problem. Nobody told the research community what the circuits did.
For fourteen years, thousands of researchers ran experiments on c432, c499, c880, c1355, c2670, c3540, c5315, c6288, and c7552. They generated test patterns for them. They diagnosed faults in them. They timed them, synthesized them, mapped them to FPGAs. They published papers about them. And nobody — nobody — knew what these circuits were actually supposed to compute.
Then in 1999, Mark Hansen, Hakan Yalcin, and John P. Hayes at the University of Michigan did what should have been done from the start. They reverse-engineered the lot. Their paper, “Unveiling the ISCAS-85 Benchmarks: A Case Study in Reverse Engineering,” published in IEEE Design & Test, is a masterpiece of detective work. They took each gate-level netlist, partitioned it into standard RTL blocks, identified the function of each block, and reconstructed the high-level architecture. The methodology was elegantly practical: Hayes assigned each circuit to a PhD student. Cheap labour, and almost certainly cheaper per insight than an LLM.
The results were revelatory. c432 turned out to be a 27-channel interrupt controller. c880 was an 8-bit ALU. c6288 was a 16×16 multiplier. c7552 was a 32-bit adder/comparator. c499 and c1355 were both 32-bit single-error-correcting circuits — the same function, different implementations. These weren’t abstract mathematical constructs. They were real designs, ripped from real hardware, and for a decade and a half the research community had been studying them the way archaeologists study pottery shards: knowing the shape but not the purpose.
Hayes’s contribution is profound and under-appreciated. By recovering the behavioral specifications, he gave the community something it had never had: the ability to test at the functional level, to verify synthesis results against intended behaviour, to use hierarchical structure for more efficient test generation. The high-level models are still available, complete with annotated schematics and structural Verilog, and they remain useful tools nearly three decades later.
Why This Matters
There is a thread connecting the Правец, the ISCAS reversal, and the work I’ve been doing with LyDiA and qbf-designer.
Reverse engineering is synthesis in reverse. When Hayes looked at c6288 and deduced it was a multiplier, he was doing — by hand, with extraordinary patience — what a diagnostic engine does automatically: given a circuit and its behaviour, determine its function. When Marangozov looked at the Apple II and built the IMKO-1, he was doing technology transfer through structural analysis. And when Johan de Kleer described synthesis as “diagnosing a circuit into existence,” he was observing that the mathematical machinery is the same in both directions. Start with a broken specification (nothing works, every gate is “faulty”), and ask: what collection of “repairs” (gate placements) would make the circuit compute the desired function?
This is the ∃∀ structure I discussed in Diagnosing Circuits into Existence — the same quantifier alternation, the same miter-based equivalence checking, the same PSPACE-hard satisfaction problems. Diagnosis, synthesis, and reverse engineering are three faces of the same formal object. The only difference is which variables you fix and which you solve for.
The ISCAS-85 benchmarks are, incidentally, the circuits that LyDiA diagnoses. When I demonstrate model-based diagnosis on c432, I am diagnosing a 27-channel interrupt controller — I just didn’t know that for the first several years of my PhD. Thank you, Professor Hayes.
The Moral
The current approach to technology is to build something forward: throw compute at a model, train it on everything, and see what comes out. Reverse engineering goes the other way: take something that exists, understand its structure, and extract meaning. One approach requires billions of dollars and produces systems that cannot explain themselves. The other requires patience and produces understanding.
Bulgaria built a computer industry on reverse engineering. Hayes rebuilt the foundations of benchmark-driven EDA research by reversing fourteen-year-old circuits. I am building a company on the formal connection between taking circuits apart and putting them together.
None of this requires a strategic enabler for enterprise-wide transformation. It requires mathematics, a soldering iron, and the willingness to look at something carefully until you understand what it does.
Amazon’s weekly operations meeting in March reportedly focused on a “trend of incidents” characterised by “high blast radius” and “Gen-AI assisted changes.” The Financial Times, which saw the briefing note, reported that AI-generated code had been implicated in a series of outages — including one that took down Amazon’s entire e-commerce website for several hours. Amazon’s response was to deny the problem existed, which is the corporate equivalent of the AI itself: confidently wrong and hoping nobody checks. James Gosling, the creator of Java, who left AWS in 2024, was less diplomatic. He observed that the company’s AI-driven restructuring had “demolished” the teams responsible for infrastructure stability, and that the ROI analysis behind the decision was, in his words, “disastrously shortsighted.” One does not need a diagnostic engine to identify the fault here. A company replaced the engineers who understood its systems with a technology that does not, and the systems fell over. The circuit breaker that the AI removed — the one it classified as “redundant” — had been added after a previous outage. The AI could not distinguish a safety mechanism from dead code, because it had no model of the system. It had statistics. Statistics told it the breaker rarely fired. A model would have told it why.
This is the difference between machine learning and model-based reasoning, and it is the difference that this post — and the toolchain I am releasing today — is about.
An Unexpected Reception
Yesterday’s post announcing qbf-designer, a tool for exact digital circuit synthesis via Quantified Boolean Formula solving, generated rather more attention than I had anticipated. Twenty-two thousand LinkedIn impressions, a hundred-odd reactions, and five hundred profile views in twenty-four hours, for a post about problems at the second level of the polynomial hierarchy and FPGA technology mapping. One concludes that there is an audience for work that produces correct answers, even — or perhaps especially — in an era when the prevailing technology cannot reliably tell you which end of a circuit is up.
Dusting Off the Arsenal
To continue with my plans for commercialising formal methods for EDA through Llama Logic Corporation, I have to excavate, modernise, and release the full inventory of tools and concepts I have built over nearly two decades. There are many reusable components in this stack — logic representations, solver bindings, encoding schemes, diagnostic algorithms — and they need to be cleaned up, documented, and made available. The qbf-designer release was the first. Today’s is the second.
Today I am releasing LyDiA, a language and toolchain for Model-Based Diagnosis. LyDiA was the core of my doctoral research at Delft University of Technology. I will not be using LyDiA itself going forward — the modern llogic packages have fixed all of its imprecise notions and provide a cleaner foundation for everything I am building — but LyDiA was where it all started. It was my first serious work on the diagnosis of circuits, and it contains ideas and algorithms that remain relevant. It deserves to be available.
Model-Based Diagnosis in 15 Seconds
The demo takes two inputs. The model (2adder-weak.sys) describes a two-bit full adder — a hierarchical composition of half-adders built from XOR and AND gates. Every gate has a Boolean health variable: true means the gate works correctly, false means it is faulty and its output is unconstrained. We do not specify how a gate fails, only that its output can no longer be trusted. This is called a weak fault model.
The observation (2adder.obs) records what actually happened: specific values on the inputs and outputs of the circuit that are inconsistent with correct behaviour. Something is broken. We do not know what. The diag command hands both files to the GOTCHA engine — which computes all minimal sets of component failures that explain the discrepancy. Not one guess. Not the most likely answer. Every combination of gate failures that is logically consistent with the model and the observation, with no redundancy.
The fm command lists the results: six double-fault diagnoses, each a minimal set of gates whose simultaneous failure is sufficient to produce the observed misbehaviour. For example, d4 = { !FA.HA1.X.h, !FA.O.h } means the XOR gate in the first half-adder and the OR gate are both broken. There is no single-fault explanation — at least two gates must be faulty, and the engine has proven this by exhaustive enumeration.
Why Circuits?
Writing software to diagnose a fabricated IC does not make practical sense. You would use ATPG and scan chains for that. We use digital circuits as benchmarks because they have the properties that matter for diagnosis research: compositional structure, many components, well-defined fault models, and known-correct reference behaviour. These are the same properties that make diagnosis hard in complex engineered systems generally. This is why the ISCAS-85 suite has been the standard MBD benchmark for thirty years.
Where diagnosis does apply directly in EDA is design verification. Suppose an engineer places a NAND gate instead of an AND gate for the carry computation in the adder above. The circuit passes some tests but fails on specific input vectors. The diagnostic engine, given the intended specification and the observed misbehaviour, will isolate the carry gate as the faulty component — even if the designer has never seen this particular mistake before, even if there are multiple simultaneous design errors. It reasons from the structure of the circuit, not from a database of past bugs.
The Modelling Problem
During my early attempts at commercialisation, I encountered a pattern that I suspect anyone in formal methods has seen. People looked at LyDiA diagnosing circuits and said: “Wonderful. Can it diagnose my HVAC system? My chemical plant? My supply chain?” And so they tried to model non-circuits as circuits, and things did not work, because the difficulty of modelling is the hard part.
Circuit diagnosis is tractable in part because digital circuits have a natural, compositional, Boolean structure. An AND gate is an AND gate. An HVAC system is a tangle of continuous dynamics, feedback loops, thermal gradients, and human behaviour. Cramming that into a Boolean framework requires heroic abstraction, and the resulting models are either too coarse to be useful or too large to be solvable. The aerospace fuel system model included in LyDiA — with its typed fault modes for leaking tanks, stuck sensors, and degraded pumps — hints at what multi-valued modelling can achieve, but it remains a toy compared to the real thing.
That said, LyDiA was never only about circuits. The distribution includes models of the N-queens problem, map colouring, Sudoku, and SEND+MORE=MONEY — general constraint satisfaction problems expressed in the same language. The diagnostic framework is, at its core, a constraint solver with a notion of health variables. This generality is both its strength and its curse: it can express anything, but making it useful for a specific domain requires domain expertise that no tool can substitute.
What LyDiA Got Wrong: Probability
LyDiA assigns fault probabilities to components — each gate gets a prior like 0.99 healthy, 0.01 faulty — but the probabilistic reasoning was never worked out correctly. The probabilities were treated as independent priors, multiplied together to rank diagnoses, with no rigorous account of how observations update beliefs or how correlations between faults propagate through the system.
The correct formulation turns out to be a #P problem — a counting problem. To compute the exact posterior probability of a diagnosis, you need to count the satisfying assignments of the diagnostic formula: how many ways can the internal signals of the circuit be assigned such that the model, the observation, and a given fault assumption are all consistent? The probability of a diagnosis is the ratio of its satisfying assignment count to the total. This is model counting, and it is #P-complete — harder than NP.
One consequence is that all diagnostic probabilities are rationals. They are ratios of integers — counts of discrete satisfying assignments. This has some puzzling implications for the relationship between fault probability and physical failure rates that I have not yet fully worked out.
There is also a quantum angle. Faults are inherently stochastic — a gate either works or it does not, and before you test it, the fault state is indeterminate in precisely the sense that a qubit is indeterminate before measurement. I showed in earlier work that placing health qubits in superposition and propagating them through a quantum circuit that mirrors the classical circuit under diagnosis computes the full probability distribution over all diagnoses simultaneously. This connects to von Neumann’s foundational work on the relationship between logic and probability. The practical implication is Grover’s algorithm: a quadratic speedup for searching the diagnostic space. I need to finish this work and implement a proper Grover-based diagnostic engine. It is on the list.
Why Machine Learning Cannot Do This
In February, a company called Algorhythm Holdings — formerly a manufacturer of karaoke machines, with a market capitalisation of six million dollars — announced that its AI platform could “optimise” freight logistics, scaling volumes by 300–400% without adding staff. The announcement wiped seventeen billion dollars off U.S. transportation stocks in a single day. C.H. Robinson fell 15%. RXO fell 20%. The Russell 3000 Trucking Index dropped 6.6%. DHL, DSV, and Kuehne+Nagel followed in Europe. All of this because a former karaoke company claimed, in effect, to have solved optimal planning — a problem that is PSPACE-complete. If Alan Turing and Stephen Cook could be reached for comment, I suspect they would have questions.
The same magical thinking pervades “AI for diagnostics.” A machine learning model trained on historical failures will recognise patterns it has seen before. Show it a novel fault — a combination that never appeared in the training data — and it has nothing to generalise from. It will either misclassify the failure or express high confidence in a wrong answer. This is not a limitation that more data or a larger model can fix. It is a structural property of inductive inference: you cannot learn what you have not observed, and complex systems fail in ways that are combinatorially vast and fundamentally unpredictable from examples alone.
Model-based diagnosis does not have this problem. If you have a model of the system, you can diagnose faults you have never observed, in configurations you have never tested, because the reasoning is deductive rather than inductive. The SAT solver asks: is there an assignment of health variables that is consistent with the model and the observations? The answer is provably correct with respect to the model. This is why NASA uses model-based diagnosis for spacecraft and why the automotive industry uses it for on-board diagnostics. Nobody uses a neural network to diagnose a flight-critical system. The neural network might get it right 95 percent of the time. The other 5 percent is a smoking crater.
What’s Next
The modern diagnosis packages in llogic have addressed all of LyDiA’s imprecisions — cleaner encodings, correct probabilistic inference, proper multi-valued support — but those are a story for a separate post.
There is also Lydia-NG, a framework I built that extends model-based diagnosis to analog systems using a built-in SPICE simulation engine. Rethinking Lydia-NG connects us directly to the analog side of EDA — a domain where formal methods have barely made an appearance and where the tools are, to put it charitably, showing their age.
And that is the longer ambition. Cadence Virtuoso dates from 1991 — thirty-five years old. Vivado is newer (2012), but its place-and-route lineage descends from NeoCAD, acquired in 1995, and its synthesis from MINC, acquired in 1998. Synopsys Design Compiler has been around since the late 1980s. The EDA industry is running on architectural foundations that predate the web browser. These tools work — in the sense that a 1991 Toyota also works — but the algorithms inside them are heuristic, the interfaces are hostile, and nobody has rethought the fundamentals in decades.
The goal of Llama Logic Corporation is to challenge this. Modern EDA with proper AI-augmented formal methods — analog, digital, and FPGA. New languages. New solvers. New tools. Not “AI for EDA” in the Silicon Valley sense of wrapping an LLM around Verilog and hoping for the best, but the real thing: algorithms with correctness guarantees, backed by the mathematical foundations that already exist and that the industry has been too comfortable to adopt.
In the next instalment, I will demonstrate qbf-designer doing FPGA technology mapping — covering a small circuit with k-input Look-Up Tables. The formal methods stack is growing. The software works. It does not hallucinate.
Cadence recently unveiled ChipStack AI, which El Reg memorably described as “vibe coding for chips.” The idea is that an LLM agent will design your next processor for you, provided you don’t mind the occasional hallucinated transistor. One Reg commenter recalled Jensen Huang’s declaration that nobody needs to learn programming anymore, and suggested he try designing his next GPU with it. Quite. Meanwhile, a water desalination company spent $200,000 on AI-generated engineering advice that turned out to be — and I use the technical term — wrong. They then built a second AI to filter out the nonsense from the first one, which is the silicon valley equivalent of hiring a second drunk to drive the first one home. One does wonder what the industry will achieve once it sobers up. In the meantime, I have been doing something unfashionable: using mathematics to design circuits that are provably correct.
Today I am releasing qbf-designer, a tool for exact digital circuit synthesis from arbitrary component libraries via Quantified Boolean Formula solving. It is the top of a dependency stack that has also been modernised and released: llogic for logic representation, transformation, and solving; lcfgen for generating circuit primitives used both in the QBF encoding itself and as benchmark specifications; and a collection of solver bindings — pydepqbf, pylgl, pyllq, and pycudd — that connect the Python layer to the C/C++ solvers doing the actual heavy lifting. The software works. It synthesises provably minimal circuits from specifications. It found a five-gate full-subtractor that improves on the seven-gate textbook design. It does not hallucinate.
Now, explaining what “provably minimal circuit design” actually means turns out to require rather more than a single blog post — so this is the first in a series. The short version: given a functional specification (“I want a circuit that adds two numbers”) and a bag of components (“here are some AND, OR, and XOR gates”), find the smallest circuit that does the job. The practical application is technology mapping for FPGAs, where you need to cover a circuit with k-input Look-Up Tables using as few LUTs as possible. The silicon is already on the chip and you have already paid for it — every LUT you save is space freed for more logic, letting you fit a larger design onto the same device. Current industry tools — Vivado, Yosys — use heuristics for this. qbf-designer gives you the exact answer, at least for sub-circuits small enough to chew on. Early results are promising: on a 2-bit comparator mapped to 3-LUTs, the solver finds a 5-LUT implementation where heuristic methods produce 6. One does not need to be a venture capitalist to notice that 5 is fewer than 6.
There is a fundamental difference between this work and the “AI for chip design” circus currently touring Silicon Valley. Circuit synthesis — the problem of finding a minimum-size circuit equivalent to a specification — sits at the second level of the polynomial hierarchy (Σ₂ᵖ-complete, for those keeping score). This is not a problem you can solve by autocompleting Verilog. It has a precise computational complexity classification, a formal proof of correctness, and a guarantee of optimality. In other words, it is science, the kind that involves theorems rather than pitch decks, and where “it works” means something more rigorous than “the demo didn’t crash during the investor meeting.”
My interest in circuit synthesis comes from an unexpected direction: breaking things. I spent years working on Model-Based Diagnosis of digital circuits — the problem of figuring out which component in a circuit has failed, given observed misbehaviour. My colleague Johan de Kleer, who has been thinking about this sort of thing since before most AI entrepreneurs were born, used to describe synthesis as “diagnosing a circuit into existence.” The idea is beautifully perverse: start with an empty circuit, treat the absence of every gate as a “fault,” and ask the diagnostic engine what collection of fixes would make the circuit behave like, say, a 32-bit ALU. It turns out that the mathematical machinery for diagnosis and synthesis is nearly identical — the same ∃∀ quantifier structure, the same miter-based equivalence checking, the same PSPACE-hard satisfaction problems. The only difference is whether you are looking for what went wrong or what should be there in the first place.
The theoretical foundations and experimental results have been written up and submitted to Constraints, a journal that publishes work reviewed by people who can tell the difference between a proof and a press release. The paper covers the QBF encoding, the universal component cell, the configurable interconnection fabric, symmetry breaking, and extensive benchmarks on arithmetic circuits, 74XXX integrated circuits, and exact synthesis function sets. I mention this not to boast but to draw a gentle contrast with the prevailing approach to AI research in the Valley, where the peer review process consists of checking whether the blog post got enough likes on Twitter X and the replication methodology is “we lost the weights.” Should the reviewers find fault with the work, they will at least be able to point to a specific equation rather than gesturing vaguely at a loss curve and muttering about emergence.
In the next instalment, I will demonstrate qbf-designer doing FPGA technology mapping — taking a circuit, mapping it to k-input Look-Up Tables, and producing a result that uses fewer LUTs than Xilinx Vivado. Not by a little. Not by accident. By mathematics.
It is Friday. El Reg informs us that 45 percent of AI-generated code now ships with security flaws, that vibe-coded apps are leaking student data to unauthenticated attackers, and that rogue AI agents have learned to escalate privileges and exfiltrate secrets without being asked. In this climate of automated incompetence, I thought it might be instructive to look at some code written by a human, with a book, in 1999. Today we are going down memory lane — this code has never once hallucinated a dependency.
The Dig
Because everything I do is technical, even nostalgia comes with a tarball. I unearthed this:
SCL — the Small Crypto Library — and its companion SSSL, the Small Secure Socket Library. Approximately 20,000 lines of C++ implementing, from scratch: a bignum library, RSA, DSA, ElGamal, Rabin-Williams, Blum-Goldwasser, Diffie-Hellman, MQV, all five AES candidates (Rijndael was selected in October 2000, so I was ahead of the news cycle), seven hash functions, seven block cipher modes, DER encoding, a secure socket layer with protocol negotiation, and the beginnings of a TLS 1.0 implementation. Written between 1999 and 2001. I was 22.
Now, it is received wisdom that when programmers look at their old code, they recoil in horror, as one might upon discovering a photograph of oneself in flared trousers at a school disco. I looked at mine and thought: actually, this is rather good.
This puts me in mind of Bill Bryson’s observation in Neither Here Nor There about his friend Stephen Katz’s relationship with women. Bryson notes that most men, as they age, gradually lower their standards. Katz, however, had actually raised his — he had started from such a comprehensively low base that the only possible direction was up. My situation is the inverse but structurally identical: the class hierarchy is clean, the block cipher modes compose correctly, the DER encoder works. I looked at 22-year-old me’s code with twenty-five more years of context, and the younger version passed review. Standards were apparently already set.
The Story
Some context. In the summer of 1999, I was in Varna, Bulgaria, teaching UNIX courses to save money and waiting for my B.Sc. to finish. I ordered Bruce Schneier’s Applied Cryptography from Amazon. It cost me a significant fraction of a Bulgarian salary. The book arrived. I read it. Then I did what any reasonable person would do: I implemented everything in it.
The test vectors in the repository? Typed by hand from Schneier’s appendices. Every single DES permutation. Every Blowfish round. The IDEA vectors. The lot. The first three lines of the test vector file read:
# This is a comment.
# I like comments very much.
# The next line is empty.
In June 2000, I graduated and made aliyah to Israel, where I joined Zend Technologies in Ramat Gan — the company behind the PHP language engine. The crypto library came with me. The CVS timestamps tell the whole story: initial import Saturday June 9, 2001, a furious week of refactoring the DER encoding layer, and then silence. The last commit is Saturday June 16, 2001. I had renamed AddPrimitive to addValue and Write to toFile halfway through, left half the callers using the old names, commented out a constructor I hadn’t finished implementing, and walked away.
Why? Because the Israeli army started sending letters. I had already done my time as a conscript in the Bulgarian navy — an experience that cured me permanently of any romantic notions about military service — and I was not about to do it again. I left for the Netherlands in rather a hurry. The crypto library stayed behind, frozen mid-refactor, a monument to the universal truth that API migrations are never completed.
(In a parallel timeline, I might have stayed. Before Zend, I had applied for a master’s at the Weizmann Institute. The admissions interview was with Adi Shamir — yes, that Shamir, the S in RSA, whose algorithm I had just finished implementing. They asked basic mathematics questions. Nobody told me I should prepare. I didn’t get in. Ended up doing both a master’s and a doctorate at Delft instead, which worked out rather well. Zero regrets, but it remains a good dinner party story.)
The Hacktivists
Here is where it gets interesting. Towards the end of my time in Israel, I started receiving emails about SCL. They came from hacked accounts — which should have been the first clue about the correspondents — and referenced mailing lists populated by legitimate security researchers. The group was interested in using SCL+SSSL as the crypto layer for an anti-censorship tool.
For those too young or insufficiently misspent to remember: cDc was the hacking collective founded in a Texas slaughterhouse in 1984, famous for Back Orifice, for coining the term “hacktivism,” and for having a membership roster that included a future U.S. congressional candidate (Beto O’Rourke) and the man who would become DARPA’s Chief Information Officer (Peiter “Mudge” Zatko). Their offshoot Hacktivismo, led by the pseudonymous Oxblood Ruffin, was building tools to punch through national firewalls — specifically China’s.
Peekabooty was a peer-to-peer anonymity network that routed web requests through encrypted relays using standard SSL, so that censors couldn’t distinguish it from ordinary e-commerce traffic. The design started in July 2000 — the exact month I arrived at Zend. Paul Baranowski and Joey deVilla built it in Toronto, previewed it at DEF CON 9 in the summer of 2001, and it was, in concept, a direct predecessor of Tor.
They needed a small, BSD-licensed, self-contained C++ crypto library with an SSL socket layer. In 2001, the options were OpenSSL (enormous, GPL-ish, and famously hostile to casual integration) or mine. The emails were real. The interest was genuine.
This week, I made it compile on Slackware 15.0. This involved: modernising the autotools, fixing a DER API that was half-refactored in June 2001, discovering a buffer overwrite in the Rijndael key schedule that had been silently scribbling past the end of an array since 1999, finding the same bug in Blowfish, mass-replacing register keywords that C++17 no longer tolerates, const-correcting approximately four hundred string literals, and explaining to a 26-year-old libtool that SONAME is not optional.
The Rijndael bug is worth mentioning. AES-256 needs 60 round key words. The key schedule macro generates 8 per iteration. Seven iterations produce 56 — but you need indices 56 through 59, so the seventh iteration is necessary. It also writes indices 60 through 63, which are past the end of the wEncryptionKey[60] array. This has been undefined behaviour since the Clinton administration. It worked because whatever sat after the array in memory didn’t matter. The fix is to make the array 64 elements. The compiler finally noticed in 2026.
The code is now on GitLab, in the attic where it belongs:
Normal service resumes. There are things to open-source and a rather long arc to lay out properly. The crypto library was the prologue. The interesting parts come next.
This quarter, 4,500 CEOs told PwC their AI investments produced nothing. Separately, someone used AI to rewrite SQLite in Rust — 2,000 times slower. I have a cunning plan: what if we used computers to do actual computing?
Last week I said I was building a toolchain that goes from formal logic to real hardware. That post was a manifesto. This one is a receipt.
Seven days later: a full ALU — add, subtract, multiply, divide, integer factorization — running at 100MHz on a $150 Basys3 FPGA. UART command line with tab completion and history. No manual Verilog. No hand-optimized netlists. No venture capital. No pitch deck.
The arithmetic circuits are generated programmatically in llogic, translated to synthesizable Verilog by llogic2verilog, and deployed on a MicroBlaze soft processor over AXI4-Lite. The entire path from logical specification to working silicon is automated. One person, one week, open source.
The factor command brute-forces integer factorization by driving the multiplier at clock speed — 100 million candidates per second on a hobby board. Not a simulation. Not a testbench. Electrons moving through gates on a Xilinx Artix-7.
Nobody wrote this Verilog
That’s the point. Not the ALU — any undergraduate can write an adder. The point is that no human touched the HDL.
The circuit specifications live in llogic‘s DSL — a formal representation that spans Boolean formulas, CNF, circuits, and reversible/quantum circuits under one roof. lcfgen generates parameterized circuit families from that representation. llogic2verilog translates them to synthesizable Verilog. Vivado takes it the rest of the way.
Every step automated. Every component open source. No license fees, no NDAs, no EDA vendor lock-in.
What’s next
If you work on synthesis, hardware, or you’re funding research — the code is open and the board costs $150.
Next post: cryptographic circuit generators for DES and SHA, synthesized from the DSL, deployed to the FPGA. After that: an open-source architecture for SHA-1 collision hunting that makes Bitcoin’s address space look rather less comfortable. All designs public — because if the vulnerability exists, pretending otherwise is just poor manners. Any coins found can fund something useful. Clean energy. Quantum computing. Not espresso machines with a subscription model.
Ceterum censeo slopem esse delendam.
(Cato the Elder ended every speech in the Roman Senate with “Carthage must be destroyed” — regardless of the topic. This is that, but for AI slop.)