Amazon’s weekly operations meeting in March reportedly focused on a “trend of incidents” characterised by “high blast radius” and “Gen-AI assisted changes.” The Financial Times, which saw the briefing note, reported that AI-generated code had been implicated in a series of outages — including one that took down Amazon’s entire e-commerce website for several hours. Amazon’s response was to deny the problem existed, which is the corporate equivalent of the AI itself: confidently wrong and hoping nobody checks. James Gosling, the creator of Java, who left AWS in 2024, was less diplomatic. He observed that the company’s AI-driven restructuring had “demolished” the teams responsible for infrastructure stability, and that the ROI analysis behind the decision was, in his words, “disastrously shortsighted.” One does not need a diagnostic engine to identify the fault here. A company replaced the engineers who understood its systems with a technology that does not, and the systems fell over. The circuit breaker that the AI removed — the one it classified as “redundant” — had been added after a previous outage. The AI could not distinguish a safety mechanism from dead code, because it had no model of the system. It had statistics. Statistics told it the breaker rarely fired. A model would have told it why.
This is the difference between machine learning and model-based reasoning, and it is the difference that this post — and the toolchain I am releasing today — is about.
An Unexpected Reception
Yesterday’s post announcing qbf-designer, a tool for exact digital circuit synthesis via Quantified Boolean Formula solving, generated rather more attention than I had anticipated. Twenty-two thousand LinkedIn impressions, a hundred-odd reactions, and five hundred profile views in twenty-four hours, for a post about problems at the second level of the polynomial hierarchy and FPGA technology mapping. One concludes that there is an audience for work that produces correct answers, even — or perhaps especially — in an era when the prevailing technology cannot reliably tell you which end of a circuit is up.
Dusting Off the Arsenal
To continue with my plans for commercialising formal methods for EDA through Llama Logic Corporation, I have to excavate, modernise, and release the full inventory of tools and concepts I have built over nearly two decades. There are many reusable components in this stack — logic representations, solver bindings, encoding schemes, diagnostic algorithms — and they need to be cleaned up, documented, and made available. The qbf-designer release was the first. Today’s is the second.
Today I am releasing LyDiA, a language and toolchain for Model-Based Diagnosis. LyDiA was the core of my doctoral research at Delft University of Technology. I will not be using LyDiA itself going forward — the modern llogic packages have fixed all of its imprecise notions and provide a cleaner foundation for everything I am building — but LyDiA was where it all started. It was my first serious work on the diagnosis of circuits, and it contains ideas and algorithms that remain relevant. It deserves to be available.
Model-Based Diagnosis in 15 Seconds
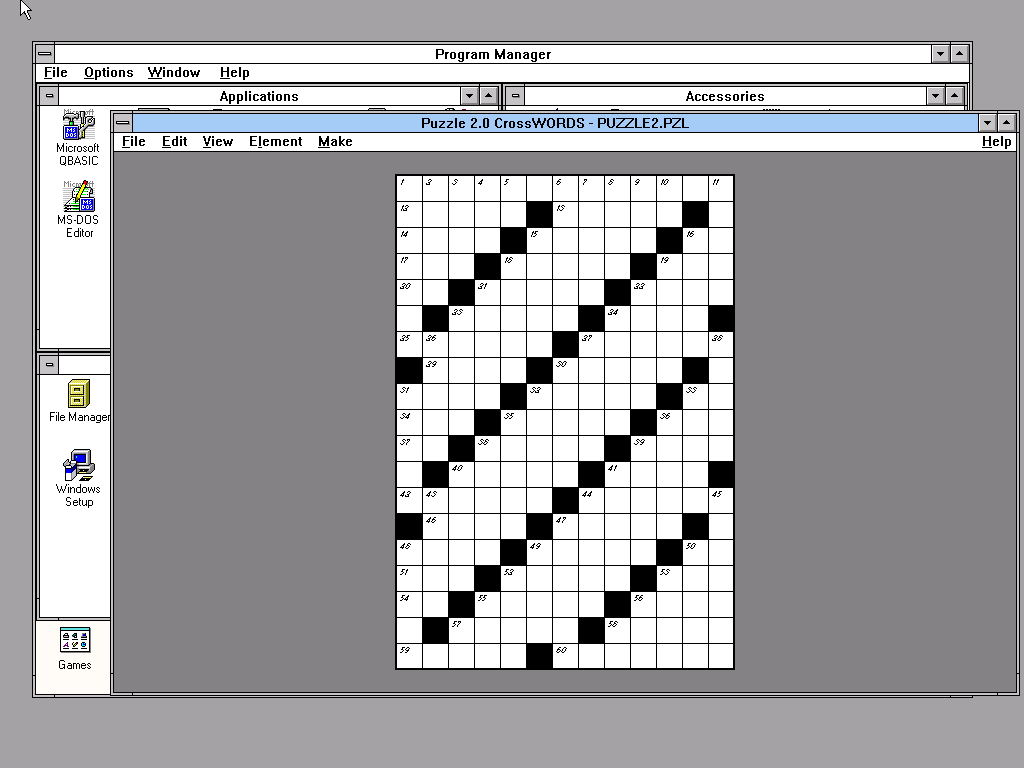
The demo takes two inputs. The model (2adder-weak.sys) describes a two-bit full adder — a hierarchical composition of half-adders built from XOR and AND gates. Every gate has a Boolean health variable: true means the gate works correctly, false means it is faulty and its output is unconstrained. We do not specify how a gate fails, only that its output can no longer be trusted. This is called a weak fault model.
The observation (2adder.obs) records what actually happened: specific values on the inputs and outputs of the circuit that are inconsistent with correct behaviour. Something is broken. We do not know what. The diag command hands both files to the GOTCHA engine — which computes all minimal sets of component failures that explain the discrepancy. Not one guess. Not the most likely answer. Every combination of gate failures that is logically consistent with the model and the observation, with no redundancy.
The fm command lists the results: six double-fault diagnoses, each a minimal set of gates whose simultaneous failure is sufficient to produce the observed misbehaviour. For example, d4 = { !FA.HA1.X.h, !FA.O.h } means the XOR gate in the first half-adder and the OR gate are both broken. There is no single-fault explanation — at least two gates must be faulty, and the engine has proven this by exhaustive enumeration.
Why Circuits?
Writing software to diagnose a fabricated IC does not make practical sense. You would use ATPG and scan chains for that. We use digital circuits as benchmarks because they have the properties that matter for diagnosis research: compositional structure, many components, well-defined fault models, and known-correct reference behaviour. These are the same properties that make diagnosis hard in complex engineered systems generally. This is why the ISCAS-85 suite has been the standard MBD benchmark for thirty years.
Where diagnosis does apply directly in EDA is design verification. Suppose an engineer places a NAND gate instead of an AND gate for the carry computation in the adder above. The circuit passes some tests but fails on specific input vectors. The diagnostic engine, given the intended specification and the observed misbehaviour, will isolate the carry gate as the faulty component — even if the designer has never seen this particular mistake before, even if there are multiple simultaneous design errors. It reasons from the structure of the circuit, not from a database of past bugs.
The Modelling Problem
During my early attempts at commercialisation, I encountered a pattern that I suspect anyone in formal methods has seen. People looked at LyDiA diagnosing circuits and said: “Wonderful. Can it diagnose my HVAC system? My chemical plant? My supply chain?” And so they tried to model non-circuits as circuits, and things did not work, because the difficulty of modelling is the hard part.
Circuit diagnosis is tractable in part because digital circuits have a natural, compositional, Boolean structure. An AND gate is an AND gate. An HVAC system is a tangle of continuous dynamics, feedback loops, thermal gradients, and human behaviour. Cramming that into a Boolean framework requires heroic abstraction, and the resulting models are either too coarse to be useful or too large to be solvable. The aerospace fuel system model included in LyDiA — with its typed fault modes for leaking tanks, stuck sensors, and degraded pumps — hints at what multi-valued modelling can achieve, but it remains a toy compared to the real thing.
That said, LyDiA was never only about circuits. The distribution includes models of the N-queens problem, map colouring, Sudoku, and SEND+MORE=MONEY — general constraint satisfaction problems expressed in the same language. The diagnostic framework is, at its core, a constraint solver with a notion of health variables. This generality is both its strength and its curse: it can express anything, but making it useful for a specific domain requires domain expertise that no tool can substitute.
What LyDiA Got Wrong: Probability
LyDiA assigns fault probabilities to components — each gate gets a prior like 0.99 healthy, 0.01 faulty — but the probabilistic reasoning was never worked out correctly. The probabilities were treated as independent priors, multiplied together to rank diagnoses, with no rigorous account of how observations update beliefs or how correlations between faults propagate through the system.
The correct formulation turns out to be a #P problem — a counting problem. To compute the exact posterior probability of a diagnosis, you need to count the satisfying assignments of the diagnostic formula: how many ways can the internal signals of the circuit be assigned such that the model, the observation, and a given fault assumption are all consistent? The probability of a diagnosis is the ratio of its satisfying assignment count to the total. This is model counting, and it is #P-complete — harder than NP.
One consequence is that all diagnostic probabilities are rationals. They are ratios of integers — counts of discrete satisfying assignments. This has some puzzling implications for the relationship between fault probability and physical failure rates that I have not yet fully worked out.
There is also a quantum angle. Faults are inherently stochastic — a gate either works or it does not, and before you test it, the fault state is indeterminate in precisely the sense that a qubit is indeterminate before measurement. I showed in earlier work that placing health qubits in superposition and propagating them through a quantum circuit that mirrors the classical circuit under diagnosis computes the full probability distribution over all diagnoses simultaneously. This connects to von Neumann’s foundational work on the relationship between logic and probability. The practical implication is Grover’s algorithm: a quadratic speedup for searching the diagnostic space. I need to finish this work and implement a proper Grover-based diagnostic engine. It is on the list.
Why Machine Learning Cannot Do This
In February, a company called Algorhythm Holdings — formerly a manufacturer of karaoke machines, with a market capitalisation of six million dollars — announced that its AI platform could “optimise” freight logistics, scaling volumes by 300–400% without adding staff. The announcement wiped seventeen billion dollars off U.S. transportation stocks in a single day. C.H. Robinson fell 15%. RXO fell 20%. The Russell 3000 Trucking Index dropped 6.6%. DHL, DSV, and Kuehne+Nagel followed in Europe. All of this because a former karaoke company claimed, in effect, to have solved optimal planning — a problem that is PSPACE-complete. If Alan Turing and Stephen Cook could be reached for comment, I suspect they would have questions.
The same magical thinking pervades “AI for diagnostics.” A machine learning model trained on historical failures will recognise patterns it has seen before. Show it a novel fault — a combination that never appeared in the training data — and it has nothing to generalise from. It will either misclassify the failure or express high confidence in a wrong answer. This is not a limitation that more data or a larger model can fix. It is a structural property of inductive inference: you cannot learn what you have not observed, and complex systems fail in ways that are combinatorially vast and fundamentally unpredictable from examples alone.
Model-based diagnosis does not have this problem. If you have a model of the system, you can diagnose faults you have never observed, in configurations you have never tested, because the reasoning is deductive rather than inductive. The SAT solver asks: is there an assignment of health variables that is consistent with the model and the observations? The answer is provably correct with respect to the model. This is why NASA uses model-based diagnosis for spacecraft and why the automotive industry uses it for on-board diagnostics. Nobody uses a neural network to diagnose a flight-critical system. The neural network might get it right 95 percent of the time. The other 5 percent is a smoking crater.
What’s Next
The modern diagnosis packages in llogic have addressed all of LyDiA’s imprecisions — cleaner encodings, correct probabilistic inference, proper multi-valued support — but those are a story for a separate post.
There is also Lydia-NG, a framework I built that extends model-based diagnosis to analog systems using a built-in SPICE simulation engine. Rethinking Lydia-NG connects us directly to the analog side of EDA — a domain where formal methods have barely made an appearance and where the tools are, to put it charitably, showing their age.
And that is the longer ambition. Cadence Virtuoso dates from 1991 — thirty-five years old. Vivado is newer (2012), but its place-and-route lineage descends from NeoCAD, acquired in 1995, and its synthesis from MINC, acquired in 1998. Synopsys Design Compiler has been around since the late 1980s. The EDA industry is running on architectural foundations that predate the web browser. These tools work — in the sense that a 1991 Toyota also works — but the algorithms inside them are heuristic, the interfaces are hostile, and nobody has rethought the fundamentals in decades.
The goal of Llama Logic Corporation is to challenge this. Modern EDA with proper AI-augmented formal methods — analog, digital, and FPGA. New languages. New solvers. New tools. Not “AI for EDA” in the Silicon Valley sense of wrapping an LLM around Verilog and hoping for the best, but the real thing: algorithms with correctness guarantees, backed by the mathematical foundations that already exist and that the industry has been too comfortable to adopt.
In the next instalment, I will demonstrate qbf-designer doing FPGA technology mapping — covering a small circuit with k-input Look-Up Tables. The formal methods stack is growing. The software works. It does not hallucinate.
The repository: LyDiA — language and toolchain for Model-Based Diagnosis.